by Christophe Salperwyck on March 25, 2018 using MOA 2017.06.
Introduction
Apache Flink is a scalable stream processing engine but doesn’t support data stream mining (it only has a batch machine learning library: FlinkML). MOA provides many data stream mining algorithms but is not intended to be distributed with its own stream processing engine.
Apache SAMOA provides a generic way to perform distributed stream mining using stream processing engines (Storm, S4, Samza, Flink..). For specific use-cases, Flink can be used directly with MOA to use Flink internal functions optimally.
In this post we will present 2 examples of how to use MOA with Flink:
- Split the data into train/test in Flink, push the learnt model periodically and use Flink window for evaluation
- Implement OzaBag logic (weighting the instances with a Poisson law) directly in Flink
Data used
In both scenario the data is generated using the MOA RandomRBF generator.
// create the generator
DataStreamSource<Example<Instance>> rrbfSource = env.addSource(new RRBFSource());
Train/test, push Model and Evaluation within Flink
The full code for this example is available in GitHub.
Train/test split
This data stream is split into 2 streams using random sampling:
- Train: to build an incremental Decision Tree (Hoeffding tree)
- Test: to evaluate the performance of the classifier
// split the stream into a train and test streams
SplitStream<Example<Instance>> trainAndTestStream = rrbfSource.split(new RandomSamplingSelector(0.02));
DataStream<Example<Instance>> testStream = TrainAndTestStream.select(RandomSamplingSelector.TEST);
DataStream<Example<Instance>> trainStream = trainAndTestStream.select(RandomSamplingSelector.TRAIN);
Model update
The model is updated periodically using the Flink CoFlatMapFunction. The Flink documentation states exactly what we want to do:
An example for the use of connected streams would be to apply rules that change over time onto elements of a stream. One of the connected streams has the rules, the other stream the elements to apply the rules to. The operation on the connected stream maintains the current set of rules in the state. It may receive either a rule update (from the first stream) and update the state, or a data element (from the second stream) and apply the rules in the state to the element. The result of applying the rules would be emitted.
A decision tree can be seen as a set of rules, so it fits perfectly with their example :-).
public class ClassifyAndUpdateClassifierFunction implements CoFlatMapFunction<Example<Instance>, Classifier, Boolean> {
private static final long serialVersionUID = 1L;
private Classifier classifier = new NoChange(); //default classifier - return 0 if didn't learn
@Override
public void flatMap1(Example<Instance> value, Collector<Boolean> out) throws Exception {
//predict on the test stream
out.collect(classifier.correctlyClassifies(value.getData()));
}
@Override
public void flatMap2(Classifier classifier, Collector<Boolean> out) throws Exception {
//update the classifier when a new version is sent
this.classifier = classifier;
}
}
To avoid sending a new model at each new learned example we use the parameter updateSize to send the update less frequently.
nbExampleSeen++;
classifier.trainOnInstance(record);
if (nbExampleSeen % updateSize == 0) {
collector.collect(classifier);
}
Performance evaluation
The evaluation of the performance is done using Flink aggregate windows function, which computes the performance incrementally.
public class PerformanceFunction implements AggregateFunction<Boolean, AverageAccumulator, Double> {
...
@Override
public AverageAccumulator add(Boolean value, AverageAccumulator accumulator) {
accumulator.add(value ? 1 : 0);
return accumulator;
}
...
}
Output
The performance of the model is periodically output, each time 10,000 examples are tested.
Connected to JobManager at Actor[akka://flink/user/jobmanager_1#-511692578] with leader session id 2639af1e-4498-4bd9-a48b-673fa21529f5.
02/20/2018 16:53:28 Job execution switched to status RUNNING.
02/20/2018 16:53:28 Source: Custom Source -> Process(1/1) switched to SCHEDULED
02/20/2018 16:53:28 Co-Flat Map(1/1) switched to SCHEDULED
02/20/2018 16:53:28 TriggerWindow(GlobalWindows(), AggregatingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer@463338d7, aggFunction=moa.flink.traintest.PerformanceFunction@5f2050f6}, PurgingTrigger(CountTrigger(10000)), AllWindowedStream.aggregate(AllWindowedStream.java:475)) -> Sink: Unnamed(1/1) switched to SCHEDULED
02/20/2018 16:53:28 Source: Custom Source -> Process(1/1) switched to DEPLOYING
02/20/2018 16:53:28 Co-Flat Map(1/1) switched to DEPLOYING
02/20/2018 16:53:28 TriggerWindow(GlobalWindows(), AggregatingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer@463338d7, aggFunction=moa.flink.traintest.PerformanceFunction@5f2050f6}, PurgingTrigger(CountTrigger(10000)), AllWindowedStream.aggregate(AllWindowedStream.java:475)) -> Sink: Unnamed(1/1) switched to DEPLOYING
02/20/2018 16:53:28 Source: Custom Source -> Process(1/1) switched to RUNNING
02/20/2018 16:53:28 TriggerWindow(GlobalWindows(), AggregatingStateDescriptor{serializer=org.apache.flink.api.java.typeutils.runtime.kryo.KryoSerializer@463338d7, aggFunction=moa.flink.traintest.PerformanceFunction@5f2050f6}, PurgingTrigger(CountTrigger(10000)), AllWindowedStream.aggregate(AllWindowedStream.java:475)) -> Sink: Unnamed(1/1) switched to RUNNING
02/20/2018 16:53:28 Co-Flat Map(1/1) switched to RUNNING
0.8958
0.9244
0.9271
0.9321
0.9342
0.9345
0.9398
0.937
0.9386
0.9415
0.9396
0.9426
0.9429
0.9427
0.9454
...
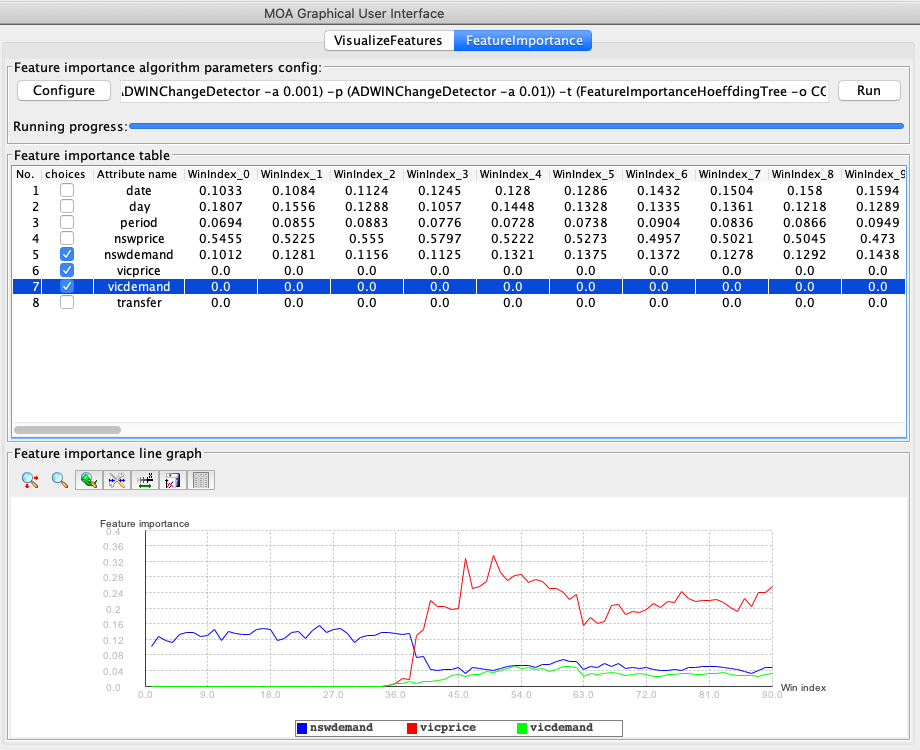
The performance of our model increase over time, as expected for on incremental machine learning algorithm!
OzaBag in Flink
Data
In this example, the data is also generated using the MOA RandomRBF generator. Many generators with the same seed run in parallel so that each classifier receive the same examples. Then to apply “online bagging (OzaBag)” each classifier put a different weight on the instance.
int k = MiscUtils.poisson(1.0, random);
if (k > 0) {
record.setWeight(record.weight() * k);
ht.trainOnInstance(record);
}
Model update
The model is updated every minute using a Flink ProcessFunction. In our case we save the model on disk, but it could be pushed into a web service or some other serving layer.
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> collector) throws Exception {
// just serialize as text the model so that we can have a look at what we've got
StringBuilder sb = new StringBuilder();
synchronized (ht) {
ht.getModelDescription(sb, 2);
}
// just collect the names of the file for logging purpose
collector.collect("Saving model on disk, file " +
// save the model in a file, but we could push to our online system!
Files.write(
Paths.get("model/FlinkMOA_" + timestamp + "_seed-" + seed + ".model"),
sb.toString().getBytes(),
StandardOpenOption.CREATE_NEW)
.toString());
// we can trigger the next event now
timerOn = false;
}
Output with a parallelism of 4
Connected to JobManager at Actor[akka://flink/user/jobmanager_1#-425324055] with leader session id 5f617fa1-7c02-4288-b305-7d97413ee2d8.
02/21/2018 16:51:05 Job execution switched to status RUNNING.
02/21/2018 16:51:05 Source: Random RBF Source(1/4) switched to SCHEDULED
02/21/2018 16:51:05 Source: Random RBF Source(2/4) switched to SCHEDULED
...
1> HT with OzaBag seed 3 already processed 500000 examples
3> HT with OzaBag seed 2 already processed 500000 examples
...
2> HT with OzaBag seed 0 already processed 1500000 examples
4> HT with OzaBag seed 1 already processed 1500000 examples
1> HT with OzaBag seed 3 already processed 2000000 examples
3> HT with OzaBag seed 2 already processed 2000000 examples
2> Saving model on disk, file model\FlinkMOA_1519228325596_seed-0.model
4> Saving model on disk, file model\FlinkMOA_1519228325596_seed-1.model
1> Saving model on disk, file model\FlinkMOA_1519228325597_seed-3.model
3> Saving model on disk, file model\FlinkMOA_1519228325603_seed-2.model
2> HT with OzaBag seed 0 already processed 2000000 examples
1> HT with OzaBag seed 3 already processed 2500000 examples
4> HT with OzaBag seed 1 already processed 2000000 examples
...
Next step
The next step would be to assess the performance of our online bagging. It might be a bit tricky here as we need to collect all classifiers and bag them, but we need to know which one to replace in the bag when there is an update.
In the meantime you can use MOA to check the performances!