Data visualization is a key aspect in data science, however tools to analyze features over time in a streaming setting are not so common[1]. The new release of MOA 20.12 includes a new module named Feature Analysis, which allows users to visualize features (tab “VisualizeFeature”) and inspect feature importances (tab “FeatureImportance”).
The feature analysis is useful to verify how the features evolve over time, check if seasonal patterns occur or observe signs of temporal dependencies, as shown below using the normalized electricity dataset.

The Feature Importance tab allows users to verify the impact of different features to the model. The methods implemented so far allow the calculation of MDI and Cover for a multitude of algorithms (all algorithms inheriting from the Hoeffding Tree[2], and any ensemble of decision trees, e.g. Adaptive Random Forest[3]). Details about how these metrics were adapted to the streaming environment are available in [4].
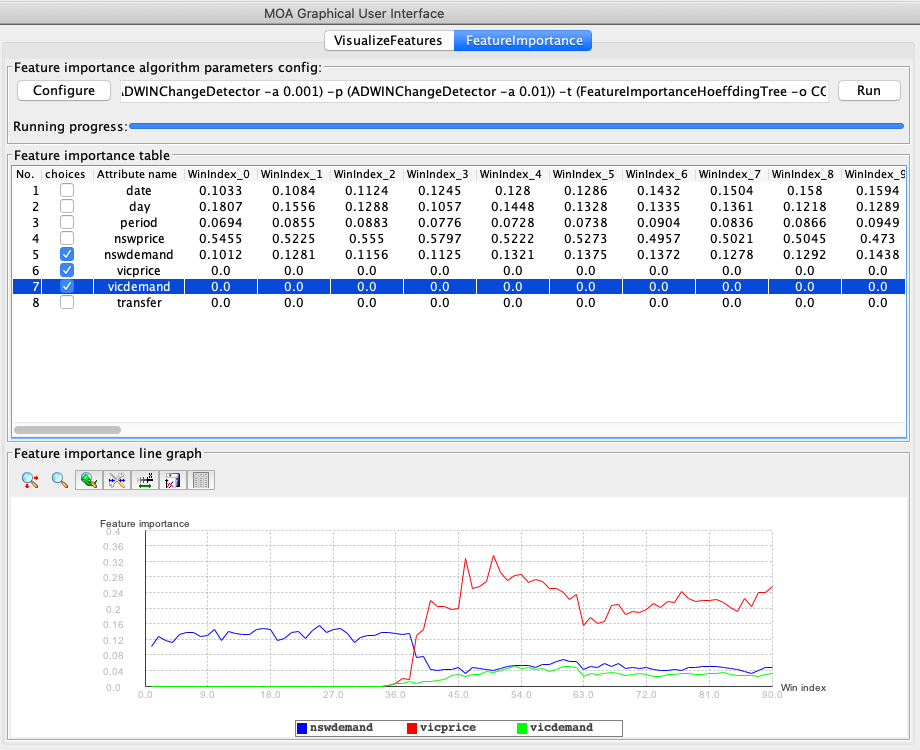
We have created a tutorial on how to use the Feature Analysis tab, available here: Tutorial 7: Feature Analysis and Feature Importance in MOA
References
- Heitor M Gomes, Jesse Read, Albert Bifet, Jean P Barddal, Joao Gama. “Machine learning for streaming data: state of the art, challenges, and opportunities.” ACM SIGKDD Explorations Newsletter (2019). ↩︎
- Pedro Domingos and Geoff Hulten. “Mining high-speed data streams.” ACM SIGKDD international conference on Knowledge discovery and data mining (2000). ↩︎
- Heitor M Gomes, Albert Bifet, Jesse Read, Jean Paul Barddal, Fabrício Enembreck, Bernhard Pfahringer, Geoff Holmes, and Talel Abdessalem. “Adaptive random forests for evolving data stream classification.” Machine Learning, Springer (2017). ↩︎
- Heitor M Gomes, Rodrigo Mello, Bernhard Pfahringer, Albert Bifet. “Feature Scoring using Tree-Based Ensembles for Evolving Data Streams.” IEEE Big Data (2019). ↩︎